
新闻
新闻资讯
联系我们
联系人:陈先生
手机:13888889999
电话:020-88888888
邮箱:youweb@126.com
地址:广东省广州市番禺经济开发区
行业资讯
sql 优化常用的方法有几种?
sql优化是一个大家都比较关注的热门话题,无论你在面试,还是工作中,都很有可能会遇到。
如果某天你负责的某个线上接口,出现了性能问题,需要做优化。那么你首先想到的很有可能是优化sql语句,因为它的改造成本相对于代码来说也要小得多。
最近无意间获得一份BAT大厂大佬写的刷题笔记,一下子打通了我的任督二脉,越来越觉得算法没有想象中那么难了。
[BAT大佬写的刷题笔记,让我offer拿到手软](这位BAT大佬写的Leetcode刷题笔记,让我offer拿到手软)
那么,如何优化sql语句呢?
这篇文章从15个方面,分享了sql优化的一些小技巧,希望对你有所帮助。
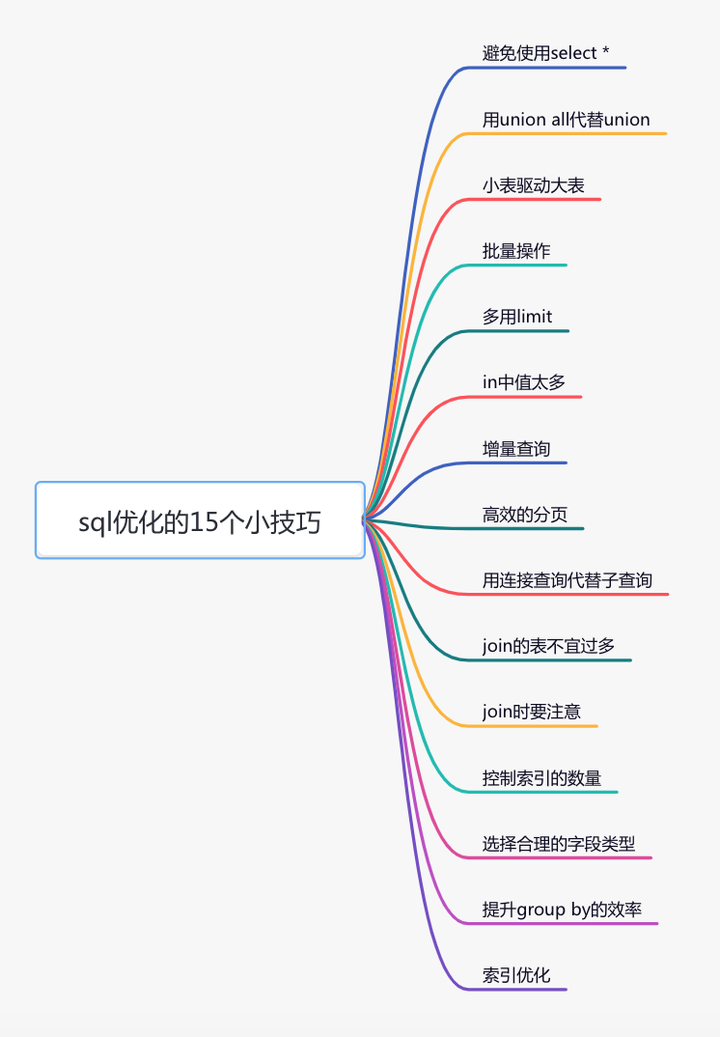
很多时候,我们写sql语句时,为了方便,喜欢直接使用select *,一次性查出表中所有列的数据。
反例:
select * from user where id=1;
在实际业务场景中,可能我们真正需要使用的只有其中一两列。查了很多数据,但是不用,白白浪费了数据库资源,比如:内存或者cpu。
此外,多查出来的数据,通过网络IO传输的过程中,也会增加数据传输的时间。
还有一个最重要的问题是:select *不会走覆盖索引,会出现大量的回表操作,而从导致查询sql的性能很低。
那么,如何优化呢?
正例:
select name,age from user where id=1;
sql语句查询时,只查需要用到的列,多余的列根本无需查出来。
我们都知道sql语句使用union关键字后,可以获取排重后的数据。
而如果使用union all关键字,可以获取所有数据,包含重复的数据。
反例:
(select * from user where id=1)
union
(select * from user where id=2);
排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。
所以如果能用union all的时候,尽量不用union。
正例:
(select * from user where id=1)
union all
(select * from user where id=2);
除非是有些特殊的场景,比如union all之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用union。
小表驱动大表,也就是说用小表的数据集驱动大表的数据集。
假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。
这时如果想查一下,所有有效的用户下过的订单列表。
可以使用in关键字实现:
select * from order
where user_id in (select id from user where status=1)
也可以使用exists关键字实现:
select * from order
where exists (select 1 from user where order.user_id=user.id and status=1)
前面提到的这种业务场景,使用in关键字去实现业务需求,更加合适。
为什么呢?
因为如果sql语句中包含了in关键字,则它会优先执行in里面的子查询语句,然后再执行in外面的语句。如果in里面的数据量很少,作为条件查询速度更快。
而如果sql语句中包含了exists关键字,它优先执行exists左边的语句(即主查询语句)。然后把它作为条件,去跟右边的语句匹配。如果匹配上,则可以查询出数据。如果匹配不上,数据就被过滤掉了。
这个需求中,order表有10000条数据,而user表有100条数据。order表是大表,user表是小表。如果order表在左边,则用in关键字性能更好。
总结一下:
- in 适用于左边大表,右边小表。
- exists 适用于左边小表,右边大表。
不管是用in,还是exists关键字,其核心思想都是用小表驱动大表。
如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?
反例:
for(Order order: list){
orderMapper.insert(order):
}
在循环中逐条插入数据。
insert into order(id,code,user_id)
values(123,'001',100);
该操作需要多次请求数据库,才能完成这批数据的插入。
但众所周知,我们在代码中,每次远程请求数据库,是会消耗一定性能的。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。
那么如何优化呢?
正例:
orderMapper.insertBatch(list):
提供一个批量插入数据的方法。
insert into order(id,code,user_id)
values(123,'001',100),(124,'002',100),(125,'003',101);
这样只需要远程请求一次数据库,sql性能会得到提升,数据量越多,提升越大。
但需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。
有时候,我们需要查询某些数据中的第一条,比如:查询某个用户下的第一个订单,想看看他第一次的首单时间。
反例:
select id, create_date
from order
where user_id=123
order by create_date asc;
根据用户id查询订单,按下单时间排序,先查出该用户所有的订单数据,得到一个订单集合。然后在代码中,获取第一个元素的数据,即首单的数据,就能获取首单时间。
List<Order> list=orderMapper.getOrderList();
Order order=list.get(0);
虽说这种做法在功能上没有问题,但它的效率非常不高,需要先查询出所有的数据,有点浪费资源。
那么,如何优化呢?
正例:
select id, create_date
from order
where user_id=123
order by create_date asc
limit 1;
使用limit 1,只返回该用户下单时间最小的那一条数据即可。
此外,在删除或者修改数据时,为了防止误操作,导致删除或修改了不相干的数据,也可以在sql语句最后加上limit。
例如:
update order set status=0,edit_time=now(3)
where id>=100 and id<200 limit 100;
这样即使误操作,比如把id搞错了,也不会对太多的数据造成影响。
对于批量查询接口,我们通常会使用in关键字过滤出数据。比如:想通过指定的一些id,批量查询出用户信息。
sql语句如下:
select id,name from category
where id in (1,2,3...100000000);
如果我们不做任何限制,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。
这时该怎么办呢?
select id,name from category
where id in (1,2,3...100)
limit 500;
可以在sql中对数据用limit做限制。
不过我们更多的是要在业务代码中加限制,伪代码如下:
public List<Category> getCategory(List<Long> ids){
if(CollectionUtils.isEmpty(ids)){
return null;
}
if(ids.size() > 500){
throw new BusinessException("一次最多允许查询500条记录")
}
return mapper.getCategoryList(ids);
}
还有一个方案就是:如果ids超过500条记录,可以分批用多线程去查询数据。每批只查500条记录,最后把查询到的数据汇总到一起返回。
不过这只是一个临时方案,不适合于ids实在太多的场景。因为ids太多,即使能快速查出数据,但如果返回的数据量太大了,网络传输也是非常消耗性能的,接口性能始终好不到哪里去。
有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。
反例:
select * from user;
如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,就是如果数据很多的话,查询性能会非常差。
这时该怎么办呢?
正例:
select * from user
where id>#{lastId}and create_time >=#{lastCreateTime}
limit 100;
按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
在mysql中分页一般用的limit关键字:
select id,name,age
from user limit 10,20;
如果表中数据量少,用limit关键字做分页,没啥问题。但如果表中数据量很多,用它就会出现性能问题。
比如现在分页参数变成了:
select id,name,age
from user limit 1000000,20;
mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,这个是非常浪费资源的。
那么,这种海量数据该怎么分页呢?
优化sql:
select id,name,age
from user where id > 1000000 limit 20;
先找到上次分页最大的id,然后利用id上的索引查询。不过该方案,要求id是连续的,并且有序的。
还能使用between优化分页。
select id,name,age
from user where id between 1000000 and 1000020;
需要注意的是between要在唯一索引上分页,不然会出现每页大小不一致的问题。
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
子查询的例子如下:
select * from order
where user_id in (select id from user where status=1)
子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select o.* from order o
inner join user u on o.user_id=u.id
where u.status=1
根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个。
反例:
select a.name,b.name.c.name,d.name
from a
inner join b on a.id=b.a_id
inner join c on c.b_id=b.id
inner join d on d.c_id=c.id
inner join e on e.d_id=d.id
inner join f on f.e_id=e.id
inner join g on g.f_id=f.id
如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。
并且如果没有命中中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。
所以我们应该尽量控制join表的数量。
正例:
select a.name,b.name.c.name,a.d_name
from a
inner join b on a.id=b.a_id
inner join c on c.b_id=b.id
如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。
不过我之前也见过有些ERP系统,并发量不大,但业务比较复杂,需要join十几张表才能查询出数据。
所以join表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。
我们在涉及到多张表联合查询的时候,一般会使用join关键字。
而join使用最多的是left join和inner join。
- left join:求两个表的交集外加左表剩下的数据。
- inner join:求两个表交集的数据。
使用inner join的示例如下:
select o.id,o.code,u.name
from order o
inner join user u on o.user_id=u.id
where u.status=1;
如果两张表使用inner join关联,mysql会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
使用left join的示例如下:
select o.id,o.code,u.name
from order o
left join user u on o.user_id=u.id
where u.status=1;
如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
要特别注意的是在用left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
那么,问题来了,如果表中的索引太多,超过了5个该怎么办?
这个问题要辩证的看,如果你的系统并发量不高,表中的数据量也不多,其实超过5个也可以,只要不要超过太多就行。
但对于一些高并发的系统,请务必遵守单表索引数量不要超过5的限制。
那么,高并发系统如何优化索引数量?
能够建联合索引,就别建单个索引,可以删除无用的单个索引。
将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase等,在业务表中只需要建几个关键索引即可。
char表示固定字符串类型,该类型的字段存储空间的固定的,会浪费存储空间。
alter table order
add column code char(20) NOT NULL;
varchar表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。
alter table order
add column code varchar(20) NOT NULL;
如果是长度固定的字段,比如用户手机号,一般都是11位的,可以定义成char类型,长度是11字节。
但如果是企业名称字段,假如定义成char类型,就有问题了。
如果长度定义得太长,比如定义成了200字节,而实际企业长度只有50字节,则会浪费150字节的存储空间。
如果长度定义得太短,比如定义成了50字节,但实际企业名称有100字节,就会存储不下,而抛出异常。
所以建议将企业名称改成varchar类型,变长字段存储空间小,可以节省存储空间,而且对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
我们在选择字段类型时,应该遵循这样的原则:
- 能用数字类型,就不用字符串,因为字符的处理往往比数字要慢。
- 尽可能使用小的类型,比如:用bit存布尔值,用tinyint存枚举值等。
- 长度固定的字符串字段,用char类型。
- 长度可变的字符串字段,用varchar类型。
- 金额字段用decimal,避免精度丢失问题。
还有很多原则,这里就不一一列举了。
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
反例:
select user_id,user_name from order
group by user_id
having user_id <=200;
这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
正例:
select user_id,user_name from order
where user_id <=200
group by user_id
使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。
sql优化当中,有一个非常重要的内容就是:索引优化。
很多时候sql语句,走了索引,和没有走索引,执行效率差别很大。所以索引优化被作为sql优化的首选。
索引优化的第一步是:检查sql语句有没有走索引。
那么,如何查看sql走了索引没?
可以使用explain命令,查看mysql的执行计划。
例如:
explain select * from `order` where code='002';
结果:

通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:

如果你想进一步了解explain的详细用法,可以看看我的另一篇文章《explain | 索引优化的这把绝世好剑,你真的会用吗?》
说实话,sql语句没有走索引,排除没有建索引之外,最大的可能性是索引失效了。
下面说说索引失效的常见原因:
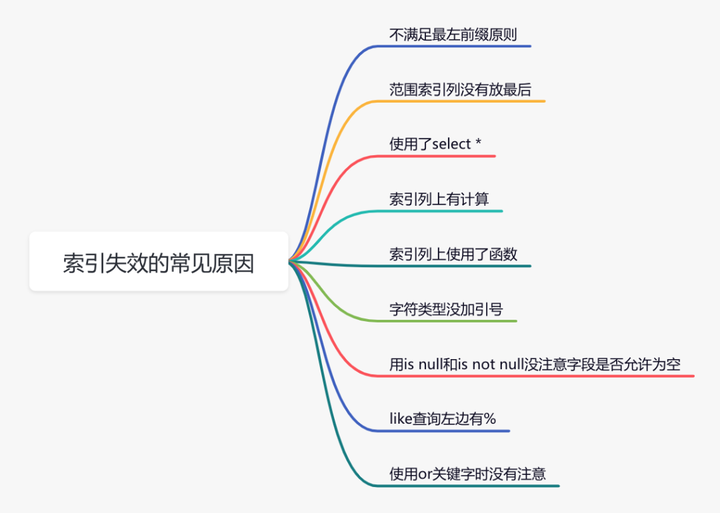
如果不是上面的这些原因,则需要再进一步排查一下其他原因。
此外,你有没有遇到过这样一种情况:明明是同一条sql,只有入参不同而已。有的时候走的索引a,有的时候却走的索引b?
没错,有时候mysql会选错索引。
必要时可以使用force index来强制查询sql走某个索引。
至于为什么mysql会选错索引,后面有专门的文章介绍的,这里先留点悬念。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
链接:https://pan.baidu.com/s/1UECE5yuaoTTRpJfi5LU5TQ 密码:bhbe
不会有人刷到这里还想白嫖吧?点赞对我真的非常重要!在线求赞。加个关注我会非常感激! @苏三说技术
Java突击队:http://www.susan.net.cn,一个能够快速提升java的神奇网站。
前几天跟阿里云数据库大佬电话沟通 and Google解决方案 and 问群里大佬,总结如下(都是精华):
1.数据库设计和表创建时就要考虑性能
2.sql的编写需要注意优化
3.分区
4.分表
5.分库
优化设计第一步
想要在表设计中节省空间,就必须精通各种数据类型的特点(能用在什么业务上)、长度等。
int类型只增主键字段=>4字节=>每个字节8位=>32位,在CPU加载一条指令的时候,4字节是和CPU寄存器的运算有关,如:64位,由于直接的系统一般都是32位的,所以在运算4字节的数据是刚好的,效率最高,而现今我们系统基本都是64位的时候,其实没有更好的利用好CPU运算,所以在设计表字段建议,使用8字节的主键bigint,而不是直接使用int来做主键。
uuid做主键,字符类型做主键,在CPU的加载是需要消耗更多的运算过程
char(10) 不管该字段是否存储数据,都占10个字符的存储空间
char(10) 同时存在一个坑,就是存储abc数据后改数据库字段的值为“abc 7个空格 ”,在精准查询(where)就必须带上后面的7个空格
varchar 不存的时候不占空间,存多长数据就占多少空间
优化设计第二步
如何合理的设计出符合三范式数据库表?
1NF:列不可分。每一列都是不可分割的基本数据项,如这样的设计就不合理,姓名(王五,wangwu)
2NF:1NF的基础上面,非主属性完全依赖于主关键字,如学生姓名(非主属性)就是依赖于学号(主属性)的。
3NF:属性不依赖于其它非主属性 , 消除传递依赖,如这样的设计就不合理,学号做主键,学生课程表(学号=课程),当学号修改,对应的课程表也需要修改,这就是属于传递依赖
BCNF:符合3NF,每个表中只有一个候选键
4NF:没有多值依赖
由于学号不能做主键,那用什么做主键?首先就有这样的规则:不要用业务规则来做主键,主键就应该和业务无关。
如经常用的的order_no(业务订单号),即使是唯一的,也不建议做主键的,容易产生传递依赖的问题,这样就不符合第三范式了。
优化设计第三步
数据库优化策略
1、选择小的数据类型
2、单独设计主键,并考虑分布式扩展
3、外键设计
(重要,我们之前开发都是直接使用的弱外键来设置主外键关系,而实际项目中,如果要是删除了主键对应的记录后,外键表中的记录是没有删除的,这样对于数据库的数据是很容易混乱的,不便于维护,那我要是使用的是强外键的方式,这样直接删除主键记录,没有删除外键表中的记录,这样是要报错的,这样容易找到代码上的问题,外键的设计能对于数据完整性有一个好的约束,当你开发的系统已经完全不会出现数据不完整的问题的时候,你可以考虑使用弱外键来关联表操作,也同时会省去外键消耗,具体的设置外键方法查考博客:外键及其约束理解)
4、索引设计
(对于业务上的字段,那些需要字段需要建立索引?)
5、关联关系表设计,多对一,多对多
6、读写频繁的信息,与不频繁的信息分开
(如在设计支付系统的时候,会同时存在订单表和订单记录表,订单表读写频繁,而订单记录表就管理人员用,读写一般)
7、配置表,日志表,定时任务表等
8、汇总表设计
(多表关联查询会很慢,还容易卡死的情况,可以考虑在业务上汇总,记录到汇总表)
优化设计第四步
经过业务的沉淀,积累出一些设计思路或抽取出多项目的共同点,减少开发成本
1、通用型设计
例:人员,部门,角色
2、特别设计
附件,日志,配置,监控等
3、存储设计
类型划分便于分区
4、一些附加字段
创建日期,修改日期,排序
5、流水表
类似于日志,但由业务处理结果组成,帐户变动或业务处理的中间值
方案一:优化现有mysql数据库。
优点:不影响现有业务,源程序不需要修改代码,成本最低。
缺点:有优化瓶颈,数据量过亿就玩完了。
方案二:升级数据库类型,换一种100%兼容mysql的数据库。
优点:不影响现有业务,源程序不需要修改代码,你几乎不需要做任何操作就能提升数据库性能,缺点:多花钱
方案三:一步到位,大数据解决方案,更换newsql/nosql数据库。
优点:扩展性强,成本低,没有数据容量瓶颈,
缺点:需要修改源程序代码
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
http://5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
应改为:
select id from t where name like 'abc%'
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,
因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,
其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.避免频繁创建和删除临时表,以减少系统表资源的消耗。
19.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
20.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,
以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
21.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
22.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
23.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
24.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。
在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
25.尽量避免大事务操作,提高系统并发能力。
26.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
26.使用联合(UNION)来代替手动创建的临时表
MySQL 从 4.0 的版本开始支持 UNION 查询,它可以把需要使用临时表的两条或更多的 SELECT 查询合并的一个查询中。在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。使用 UNION 来创建查询的时候,我们只需要用 UNION作为关键字把多个 SELECT 语句连接起来就可以了,要注意的是所有 SELECT 语句中的字段数目要想同。下面的例子就演示了一个使用 UNION的查询。
SELECT Name, Phone FROM client UNION SELECT Name, BirthDate FROM author
UNION
SELECT Name, Supplier FROM product
MySQL面试:left join我要怎优化?
MySQL面试:left join我要怎优化?这种形式分区是对表的行进行分区,通过这样的方式不同分组里面的物理列分割的数据集得以组合,从而进行个体分割(单分区)或集体分割(1个或多个分区)。所有在表中定义的列在每个数据集中都能找到,
所以表的特性依然得以保持。
举个简单例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录。(注:这里具体使用的分区方式我们后面再说,可以先说一点,一定要通过某个属性列来分割,譬如这里使用的列就是年份)
这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
在分区表上的操作按照下面的操作逻辑进行:
select查询:
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据
insert操作:
当写入一条记录时,分区层打开并锁住所有的底层表,然后确定哪个分区接受这条记录,再将记录写入对应的底层表
delete操作:
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作
update操作:
当更新一条数据时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据应该放在哪个分区,然后对底层表进行写入操作,并对原数据所在的底层表进行删除操作
虽然每个操作都会打开并锁住所有的底层表,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,如:innodb,则会在分区层释放对应的表锁,这个加锁和解锁过程与普通Innodb上的查询类似。
A:表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他都是历史数据
B:分区表的数据更容易维护,如:想批量删除大量数据可以使用清除整个分区的方式。另外,还可以对一个独立分区进行优化、检查、修复等操作
C:分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备
D:可以使用分区表来避免某些特殊的瓶颈,如:innodb的单个索引的互斥访问,ext3文件系统的inode锁竞争等
E:如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果非常好
F:优化查询,在where字句中包含分区列时,可以只使用必要的分区来提高查询效率,同时在涉及sum()和count()这类聚合函数的查询时,可以在每个分区上面并行处理,最终只需要汇总所有分区得到的结果。
场景:分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master
服务器无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。
因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库!
与分表策略相似,分库可以采用通过一个关键字取模的方式,来对数据访问进行路由,如下图所示:
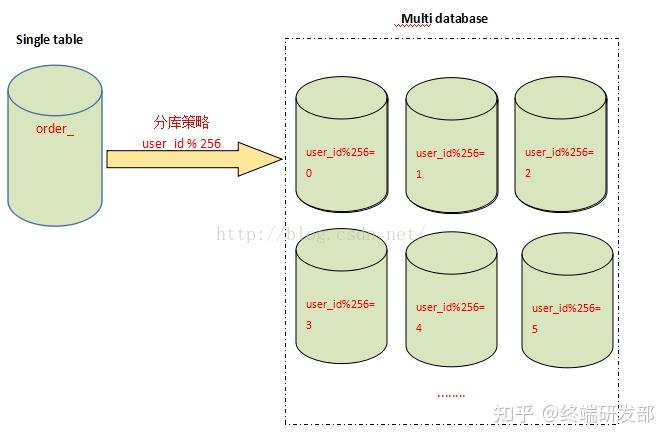
还是之前的订单表,假设user_id 字段的值为258,将原有的单库分为256个库,那么应用程序对数据库的访问请求将被路由到第二个库(258%256=2)。
a>内存——大内存、大内存位宽,尽量不要用SWAP;
b>硬盘——15000RPM、RAID5、raid10
c>CPU——64位、高主频、高缓存,高并行处理能力
d>网络——标配的千兆网卡足矣,尽可能在同一局域网内,尽量避免诸如防火墙策略等不必要的开销
a>纵向拆解
最简单的一台服务同时负责web、中间件、数据库多个角色;纵向拆解后就是数据库服务器专机专用,避免额外的服务可能导致的性能下降和不稳定性;如果将数据库服务器专机专用仍然无法满足需求,可以考虑在数据库和应用服务器之间加Memcached。
b>横向拆解
主从同步、负载均衡、高可用性集群,当单个mysql数据库无法满足日益增加的需求时,可以考虑在数据库这个逻辑层面增加多台服务器,以达到稳定、高效的效果。
http://bbs.linuxtone.org/thread-5152-1-1.html
a>64位系统可以分给单个进程更多的内存、服务调优,禁用不必要启动的服务,修改文件描述符限制,留更多的资源给mysql;
b>文件系统调优,给数据仓库一个单独的文件系统,推荐使用XFS,一般效率更高、更可靠。
c>可以考虑在挂载分区时启用noatime选项。
4,数据库服务的优化
a>使用linux/bsd操作系统进行编译安装,对编译参数进行性能优化,精简不必要启用的功能
b>合适的应用程序接口。
c>保持每个表都不要太大,可以对大表做横切和纵切;比如说我要取得某ID的lastlogin,完全可以做一张只有“ID”和 “lastlog”的小表,而非几十、几百列数据的并排大表;另外对一个有1000万条记录的表做更新比对10个100万记录的表做更新一般来的要慢
d>myisam引擎,表级锁,单锁开销小,但影响范围大,适合读多写少的表,不支持事物日志;表锁定不存在死锁
e>innodb引擎,行级锁,锁定行的开销要比锁定全表要大,但影响范围小,适合写操作比较频繁的数据表;行级锁可能存在死锁。
5,my.cnf内参数的优化;
优化总原则:给mysql的资源太少,则mysql施展不开;给mysql的资源太多,可能会拖累整个OS。
a>总体资源占用的优化;
open_files_limit——mysqld可以打开的文件的数量;
max_connections——允许的并行客户端连接数目;
max_connect_errors——允许的主机的错误连接数;
table_cache——每个链接允许打开的表的数量;
max_allowed_packet——从服务器接收的包的大小;
thread_cache_size——缓存多少个待用线程;
b>具体buffer的优化
sort_buffer_size——每个线程可以分配的缓冲区的大小;
join_buffer_size——不走索引的join操作可分配的缓冲区的大小;
query_cache_size——为查询分配的缓存;
query_cache_limit——不缓存大于该限制的查询结果;
query_cache_min_res_unit——不缓存小于该限制的查询结果;
tmp_table_size——内存内的临时表表超过该限制值,则写入硬盘;
binlog_cache_size——二进制日志文件的缓存大小;
key_buffer_size——myisam引擎的索引块共用缓冲区;
read_buffer_size——为从数据表顺序读取数据的读操作保留的缓存区的长度;
innodb_additional_mem_pool_size——InnoDB用来存储数据目录信息&其它内部数据结构的内存池的大小。你应用程序里的表越多,你需要在这里分配越多的内存。
innodb_buffer_pool_size——InnoDB用来缓存它的数据和索引的内存缓冲区的大小。理论上来说是越大越好,但要注意不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
innodb_data_file_path——innodb表空间的指定以及大小,初始表空间大一些可以减少日后自增加表空间的系统开销。
innodb_thread_concurrency——在InnoDb核心内的允许线程数量;
innodb_log_buffer_size——InnoDB用来往磁盘上的日志文件写操作的缓冲区的大小。当日志大小超过该限定时,日志会被写入磁盘,比写入内存的I/O开销大。
innodb_log_file_size——每个日志文件的大小。
max_allowed_packet——包服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小。
6,查询优化,
a>建表时表结构要合理,每个表不宜过大;在任何情况下均应使用最精确的类型。例如,如果ID列用Int是一个好主意,而用text类型则是个蠢办法;TIME列酌情使用DATE或者DATETIME。
b>索引,所有的查询都走科学的索引,单个索引命中率低时使用联合索引;
c>查询时尽量减少逻辑运算(与运算、或运算、大于小于某值的运算);
d>减少不当的查询语句,不要查询应用中不需要的列,比如说select * from 等操作。
e>减小事务包的大小;
f>将多个小的查询适当合并成一个大的查询,减少每次建立/关闭查询时的开销;
g>将某些过于复杂的查询拆解成多个小查询,和上一条恰好相反
h>建立和优化存储过程来代替大量的外部程序交互。
7,DEBUG工具:
a>vmstat——vmstat 命令报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息,
b>iostat——iostat命令报告CPU、硬盘等设备的输入输出情况,可能需要安装sysstat rpm包
c>top——动态显示当前系统的资源占用,和上文面的两个命令相比,top更侧重于进程。
d>free——显示内存和swap占用情况。
e>show processlist——显示当前运行或等待的线程,判断哪些查询语句总是处于等待状态
f>EXPLAIN——“EXPLAIN + SQL语句”查看索引使用情况。
g>show create table + “table_name” ——查看指定表的表结构
h> select count(distinct “row_name”) from "table_name";查看列内数据的唯一性,确定给哪一列创建索引。
i>create index 创建索引,并用 show processlist、top观察创建索引后的效果。
补充:关于MySQL性能优化的总结:
关于MySQL性能优化总结讲解最全的一篇文章最后呢:如果想学习技术,或者在学习技术的过程中有疑问,对编程方向的选择,可以来这里找小于哥,一个有思想有规划,被代码延误的心灵导师,可咨询offer的选择,职业规划,学习路线,技术开发中的问题
大家看完有什么不懂的可以在下方留言讨论,也可以私信问我一般看到后我都会回复的。最后觉得文章对你有帮助的话记得点个赞哦,点点关注不迷路
每天都有新鲜的干货分享!
我的回答方式不太一样,会直接给你放真实场景的正反case,以此加深你的理解。
SQL优化,算是数据库优化的一个子集。
因此,吹大牛的候选人简历上,会赫然写着”擅长MySQL数据库优化“,而吹小牛的候选人简历上,往往会写”擅长SQL优化“。
但结局是殊途同归的,就是当问他们用什么方式做的优化,他们都会说上三个字:”加索引“。
当然,好一点儿的会说可以加联合索引,它有最左前缀匹配原则(8.0以后的版本就不完全对了)之类的,还能说说覆盖索引。
那么,我的这篇文章,就好好聊聊这个面试话题。
先教大家一个小窍门,最好大家在回答面试官这个问题的时候,最好可以做到跟自己简历中项目的进行真实场景带入,这样会给面试官一种可以理论结合实践的感觉,是个大大的加分项。
举个例子,话术为:
“当时我负责电商平台的商品中心优化,我发现在展示商品列表的时候,一旦深分页就会出现加载缓慢的问题,然后我就看了一下对应的SQL语句,是这样写的:
select id, name, status, detail from product limit 10, 30;那么一旦在深分页的话,SQL语句就会变成这样:
select id, name, status, detail from product limit 100000, 30;那么MySQL的执行方式为:一共需要查100030条数据,然后丢弃前面的100000条,只返回后面的30条数据,这样做是非常浪费资源的。
于是我把SQL改为:
select id, name, status, detail from product where id > 100000 limit 30;100000为上次分页中最大的商品ID,先找到它,然后再根据主键ID扫描后续30条数据。
这样做性能很高,把SQL语句从原先的耗时4300ms,降低到了18ms。”
好了,下面我正式给大家列举一下,SQL优化的N种技巧,select * 这种的就不写了哈。
添加图片注释,不超过 140 字(可选)
上文已经讲解了,仔细看下即可。
反例:
select * from employee where address like '%通州区%';
select * from employee where address like '%通州区';正解:
select * from employee where address like '%北京市通州区';原因:
(1)全模糊查询,或者左边出现%的模糊查询,会导致索引实效,应该尽量从查询方式或表结构设计上避免。
(2)若无法避免,且数据量庞大的情况下,一定要使用ElasticSearch进行替代。
反例:
select product_id from orders where id=100
union
select product_id from orders where id=200;正解:
select product_id from orders where id=100
union all
select product_id from orders where id=200;原因:
union:对两个结果集进行并集操作,不包括重复行,相当于distinct,同时进行默认规则的排序;
union all:对两个结果集进行并集操作,包括重复行,不进行排序;
union因为要进行重复值扫描,所以在结果集庞大的情况下,效率极低,因此建议使用union all。
若结果集去重是强需求,则在应用程序代码上进行去重,因为数据库资源要比应用服务器资源更加珍贵。
straight_join功能同inner join类似,但能让左边的表来驱动右边的表,通过改变优化器对于联表查询的执行顺序的方式,获取更好的性能。
btw:若驱动表(左边)的数据量小于(被驱动表),它的执行性能要高于,驱动表(左边)的数据量大于(被驱动表)。
举个例子:
select * from t2 straight_join t1 on t2.a=t1.a;比如上面这个,如果我们事先知道t2表的数据量一定小于t1表的话,就可以使用上面的方式指定t2表为驱动表。
需要注意的点:
(1)straight_join只适用于inner join,并不适用于left join,right join。
(2)大部分情况下,MySQL优化器是可以做出正解的。因此,使用straight_join一定要慎重,因为部分情况下人为指定的执行顺序并不一定会比优化引擎要靠谱。
select * from student where school_id in (select id from school);
select * from police p where exists (select 1 from user u where u.id=p.id);如果子查询得出的结果集数据较少,主查询中的表较大且又有索引时,应该用in;反之,如果外层的主查询数据较少,子查询中的表大,又有索引时使用exists。
- 如果是exists,那么以外层表为驱动表,先被访问。
- 如果是in,那么先执行子查询。
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。所以,我们会以驱动表的快速返回为目标,目标是以小表驱动大表,这是性能优化的本质。
之前有一种比较扯淡的说法,“exists 比 in 效率高”,大家试想一下,如何一个事物在任何场景下,都优于另外一个事物,那另外一个事物就没有存在的必要性了。
反例:
delete from user;正解:
truncate user;原因:
(1)truncate是直接把表删除,然后再重建表结构,性能很高,但删除操作记录不记入日志,不能回滚。
delete语句执行删除的过程是每次从表中删除一行,性能较低,但该行的删除操作会作为事务记录在日志中保存,以便进行进行回滚操作。
(2)truncate后,表和索引所占用的空间会恢复到初始大小,而delete只是将被删除的记录标记为已删除,不会立即减少表或索引所占用的空间。
反例:
insert into student(name, sex, age) values('Tom', 1, 20);
insert into student(name, sex, age) values('Tony', 1, 18);正解:
insert into student(name, sex, age) values('Tom', 1, 20), ('Tony', 1, 18);原因:
SQL批量操作,即一次数据库操作中插入多个数据行,相比于单条插入,可减少大量的IO交互和SQL解析开销,从而提高了插入效率。
反例
select city, avg(area) from country group by city having city='beijing' or city='shanghai';正解:
select city, avg(area) from country where city='beijing' or city='shanghai' group by city;原因: 记住,无论是分组还是排序,或者多表join,如果可以的话,第一件事就是把用不到的记录先过滤掉。
反例:
select * from article where left(title, 4)='环球资讯';正解:
select * from article where title=left('环球资讯', 4);原因: 如果在索引列上使用函数,会导致索引实效。
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常会使SQL执行更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
但是,要确保没有低估需要存储的值的范围,因为在表schema中修改数据类型是一件非常耗时和痛苦的操作(特指表数据量很大的场景)。如果无法确定哪个数据类型是最好的,就选择你认为不会超过范围的最小类型。
举个例子:如果确定只需要存0—200,tinyint unsigned类型是最适合的。
char:定长,存取效率高,一般用于固定长度的表单提交数据存储,例如:身份证号,手机号,电话,密码等,长度不够的时候,会采取右补空格的方式。
varchar:不定长,更节省空间,需要用一个或者两个字节来存储数据的长度。具体规则是:如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。
varchar由于行是变长的,在UPDATE时可能使行变得比原来更长,会导致分裂页和产生碎片。
有人认为,既然varchar是变长的,那我就尽量给它设置得大一些,以备不时之需,反正没有坏处。
其实,varchar(5) 和 varchar(200)是不一样的!
我们看下《高性能MySQL》一书中的原话:
添加图片注释,不超过 140 字(可选)
因此,当你把varchar的长度调整为最小可用,是可以帮助你优化SQL排序性能的。
- 频繁作为查询条件的字段应该创建索引,频繁更新的字段不适合创建索引;
- 多表关联查询中的关联字段,查询中统计或者分组字段,查询中排序字段,应该创建索引;
- 尽量使用数据量少或区分度高的字段创建索引;
- 多条件组合查询优先创建组合索引,熟悉组合索引的最左前缀原则,不要创建冗余索引;
- 禁止使用全文索引,可以用前缀索引进行替代;
- 善于利用覆盖索引来优化查询;
- delete和update语句的where条件必须由索引,否则会导致锁表;
适当的索引策略,经过业务取舍后,可以使SQL执行得更快。
MySQL查询优化器在执行SQL语句时,会选择它认为最合适的索引,但有时却并不准确,不是实际上最快的索引,此时可以用force index人为指定索引。
force index 跟着表名后面,用于强制使用指定的索引名(key)。
如下列所示:
select * from msg force index(idx_dest_src) where dest='18736809673' and src in ('15144804019', '18674654894');据说,阿里巴巴开发者手册规定,join表的数量不应该超过3个,这个我还真没看到。
我个人觉得,多表关联需要控制量,但没必要完全一杆子拍死。
如果某个系统中,有很多多表关联的大SQL,那确实意味着表结构设计有问题,或者需要引入ES等技术方案了。
整体就这么多,后续如果有新的,我再补充。
最后,再给知友们来一波福利。
本人在之前看机会的时候,也从网上找遍了各式各类的八股文资料,但总觉得答案还不够准确,深度还有所欠缺,或是内容组织的逻辑性还不够清晰。
于是,我便自己动手,丰衣足食地自己总结了一套博采众家之长的八股文,那可真是字字斟酌,题题验证。
现在,我“大公无私”地把它分享出来,希望更多的同学可以由此受益。
Java技术栈的经典八股文最后,祝大家工作顺利,纵情向前,人人都能收获自己满意的offer。
SQL 是一种声明性语言,什么是声明性,就是你只要告诉计算机你想要从原始数据中获得什么样的数据结果即可,你也不用管它在这个过程中是先执行的啥后执行的啥。
作为数据分析师,日常使用 SQL,主要就是把自己想要的数据或者指标需求转化成 SQL 的语言逻辑去数据库等地方查询数据。
很多初学者会被网上的一些信息误导,以为 SQL 的学习要掌握到极精深的地步,恨不得深入内核嚼碎了来学。
怎么说呢,没必要,数据分析师使用 SQL 的重点就是在【查询】两个字上。
对于数据分析来说,SQL 只是工具而已,数据爆炸增长的现在,我们数据分析工具、算法这些到处都是,真正重要的是数据分析思维!
数据本身没有价值,只有经过我们客观合理的分析以后才能产生价值,比如 xxx 情况不好,问题出现在哪里?这个「客观合理」就要求数据分析思维,这需要大家去日积月累的学习和实践。
互联网时代,网络是学习最简单快速的方式,大家可以找一些大佬的视频或者多参加一些短期的特训课,看的多了操作的多了,懂的也就多了。例如知乎知学堂官方出品的数据分析实战课,经常开课时间也不是很长,有理论有实操场景,里面会告诉你怎么快速处理数据,如何看清业务问题,数据分析思路如何,业务优化怎么入手,感兴趣的可以看一下:
其实大概分的话,由浅入深分成 3 个阶段吧:
入门阶段的话就是熟练的掌握增删改查语句、运算符以及函数。
增删改查语句主要就是 select、insert、update、delete。
运算符主要就是算术运算符(+、-、*、/、%)、赋值运算符(=)、比较运算符(>、≥、<、≤)和逻辑运算符(AND、ANY、BETWEEN、IN)。
函数主要就是算法函数和时间函数等。
这一个阶段是重中之重
进阶阶段主要是熟练掌握多表查询、分组查询、子查询、组合查询等。其中最重要的就是多表查询。
工作里往往数据不是放在一个表里,而是不同的数据放在不同的表里,这就需要会从不同的表中根据业务需求来获取数据,这就需要 SQL 进行多表查询。
SELECT <Column List> FROM <Table1> JOIN <Table2> ON <Table1>.<Column1>=<Table2>.<Column1>、把数据按某个条件分为几组,然后分析每一组数据这种需要分组查询。
SELECT <Column List>, <Aggregate Function>(<Column Name>)FROM <Table Name>WHERE <Search Condition>GROUP BY <Column List>碰到比较复杂的业务的时候,需要很多 SQL 语句来完成这种复杂业务的查询,这时候就需要用子查询。
SELECT col_name FROM table_name WHERE col_name=(SELECT col_name FROM table_name WHERE .... );在单个查询中从不同的表返回类似结构的数据或者对单个表执行多个查询,按单个查询返回数据这种需要组合查询。
SELECT <Column List> FROM <Table1> UNION SELECT <Column List> FROM <Table2>高级阶段要是为了提高 SQL 的效率。都是写 SQL,怎么可以让 SQL 执行效率更快。
在这各阶段,主要要求你去学习约束、事务、锁、触发器、视图等内容。
虽然我希望大家都能掌握到第 3 阶段,但是我也知道,这对刚入行的数据分析师是有点难度的,因为这些是需要你在大量工作中积累经验。
所以对于我希望你最好掌握到第二阶段【进阶】。
---
SQL 的学习,说实话它的语法还是很简单,就和背些英语单词一样,重要的还是在于大量的练习上!
这里推荐两本书:《SQL 基础教程》、《SQL 必知必会》
这两本书的顺序呢,我建议是先《SQL 基础教程》
这本书介绍的节奏的更加平缓,并且用图示和关键字加粗更加生动地介绍知识,适合零基础的学生。
对于零基础的朋友来说 Mick 的《SQL 基础教程》更容易看懂学会,非常适合入门者学习。

看完《SQL 基础教程》以后,可以快速的翻阅 《SQL 必知必会》,其实这就是个查漏补缺和复习巩固的作用。

当然《SQL 必知必会》也可以不看,只是个可选项。
推荐这本书的原因呢,是《SQL 必知必会》有专门的练习平台供大家立马练习。只要有练习平台我都会吹爆!
网址::https://www.nowcoder.com

学习 SQL 就是用最笨的办法,大量的练,反复的练,练到吐。
SQL 在线练习网站,我比较推荐的是【牛客网】和【LeetCode】。
推荐牛客网的原因是它的 sql 板块特别顶,有很多很多很多很多的练习题可以做。
有非技术快速入门、SQL 必知必会、SQL 进阶挑战、SQL 大厂真题面试。尤其 SQL 大厂面试真题,像什么某音、某度、某东、某宝等等等等,对于想去大厂的同学很有帮助。
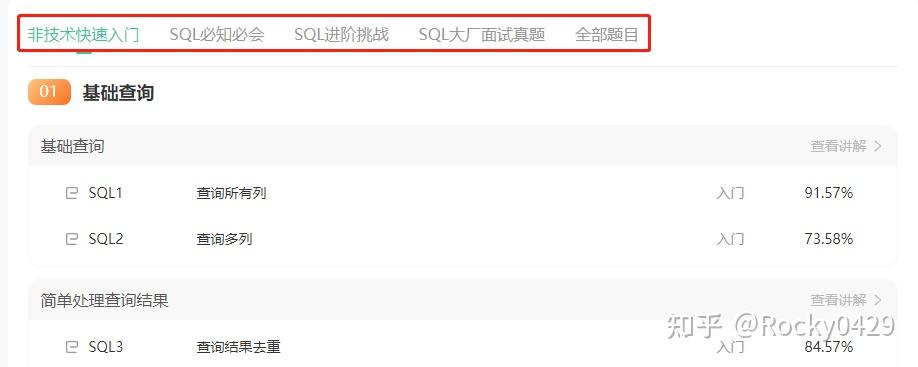
再说【LeetCode】
一般大家看到 leetcode 第一印象是刷算法题的,其实 leetcode 上也有关于 SQL 的题目。
而且可以在线测评,和评测算法题一样,也会让你很直观的看到自己所写的 SQL 的运行速度等,同样可以去借鉴别人优化好的 SQL,与自己的对比,将好的用法学会,这样的提升是很快的。
网址:https://leetcode-cn.com/
当然还有几个其它的,像 SQLZOO、SQLBolt 也不错,就不在这展开说了,下面这篇文章我写的很清楚了。
Rocky0429:在线就能用的 SQL 练习平台我给你找好了!2781 赞同 · 160 评论文章

对于回答中的书籍视频练习平台的推荐其实都是锦上添花的东西,方便你在学习的过程中少走点弯路。
但是 SQL 的学习还是我刚刚一直在回答里强调的,大量的练习+大量的练习+大量的练习!
同样,对于数据分析来说也是这样的,大量的实践练习也是必须的,多见一些场景,多深入进去研究对自己的数据分析能力提升会很大。大家可以对知乎知学堂官方出品的特训课多多关注,我多次推荐了,有实际的应用场景,更不用说实战思路和业务优化这块能让你收获满满。
希望你真的能听进去,祝早日成为数据分析大佬!
本文作者:@Rocky0429
目前,该付费内容的完整版仅支持在 App 中查看
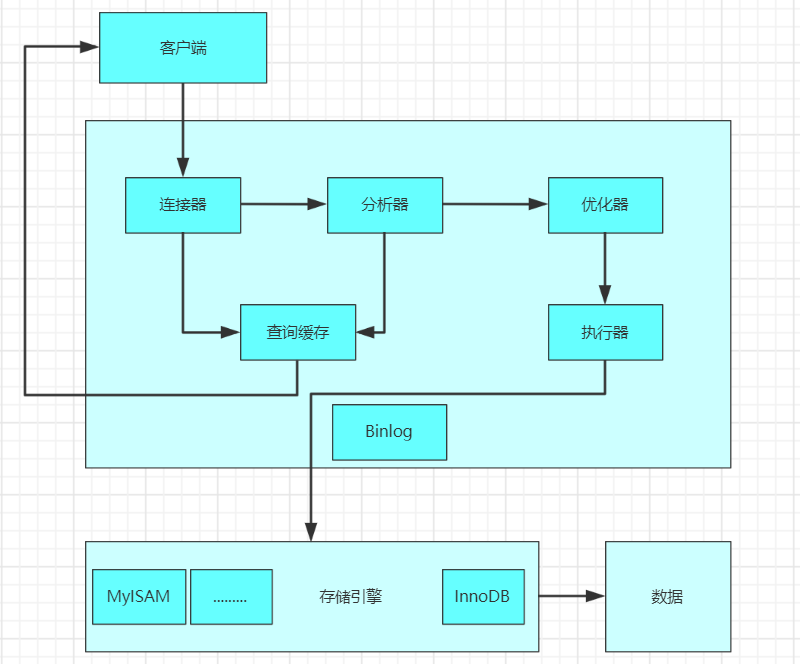
App 内查看(1)客户端发送一条查询语句到服务器;
(2)服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据;
(3)未命中缓存后,MySQL 通过关键字将 SQL 语句进行解析,并生成一颗对应的解析树,MySQL 解析器将使用 MySQL 语法进行验证和解析。
? 例如,验证是否使用了错误的关键字,或者关键字的使用是否正确;
(4)预处理是根据一些 MySQL 规则检查解析树是否合理,比如检查表和列是否存在,还会解析名字和别名,然后预处理器会验证权限;
? 根据执行计划查询执行引擎,调用 API 接口调用存储引擎来查询数据;
(5)将结果返回客户端,并进行缓存;
1、 为 WHERE 及 ORDER BY 涉及的列上建立索引
对查询进行优化,应尽量避免全表扫描,首先应考虑在 WHERE 及 ORDER BY 涉及的列上建立索引。
2、where 中使用默认值代替 null 应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,创建表时 NULL 是默认值,但大多数时候应该使用 NOT NULL,或者使用一个特殊的值,如 0,-1 作为默认值。
为啥建议 where 中使用默认值代替 null,四个原因:
(1)并不是说使用了 is null 或者 is not null 就会不走索引了,这个跟 mysql 版本以及查询成本都有关;
(2)如果 mysql 优化器发现,走索引比不走索引成本还要高,就会放弃索引,这些条件!=,<>,is null,is not null 经常被认为让索引失效;
(3)其实是因为一般情况下,查询的成本高,优化器自动放弃索引的;
(4)如果把 null 值,换成默认值,很多时候让走索引成为可能,同时,表达意思也相对清晰一点;
3、慎用!=或 <> 操作符。
MySQL 只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的 LIKE。
所以:应尽量避免在 WHERE 子句中使用!=或 <> 操作符, 会导致全表扫描。
4、慎用 OR 来连接条件
使用 or 可能会使索引失效,从而全表扫描;
应尽量避免在 WHERE 子句中使用 OR 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,
可以使用 UNION 合并查询:
select id from t where num=10
union all
select id from t where num=20
一个关键的问题是否用到索引。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用 UNION all 执行的效率更高。多个 OR 的字句没有用到索引,改写成 UNION 的形式再试图与索引匹配。
5、慎用 IN 和 NOT IN
IN 和 NOT IN 要慎用,否则会导致全表扫描。对于连续的数值,能用 BETWEEN 就不要用 IN:select id from t where num between 1 and 3。
6、慎用 左模糊 like ‘%…’
模糊查询,程序员最喜欢的就是使用 like,like 很可能让索引失效。
比如:
select id from t where name like‘% abc%’ select id from t where name like‘% abc’ 而 select id from t where name like‘abc%’才用到索引。
所以:
首先尽量避免模糊查询,如果必须使用,不采用全模糊查询,也应尽量采用右模糊查询, 即 like ‘…%’,是会使用索引的; 左模糊 like ‘%…’无法直接使用索引,但可以利用 reverse + function index 的形式,变化成 like ‘…%’; 全模糊查询是无法优化的,一定要使用的话建议使用搜索引擎,比如 ElasticSearch。 备注:如果一定要用左模糊 like ‘%…’检索, 一般建议 ElasticSearch+Hbase 架构
7、WHERE 条件使用参数会导致全表扫描。
如下面语句将进行全表扫描:
select id from t where num=@num
因为 SQL 只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推 迟到 运行时;
它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
所以, 可以改为强制查询使用索引:
select id from t with (index (索引名)) where num=@num
8、用 EXISTS 代替 IN 是一个好的选择
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in (select num from b) 用下面的语句替换: select num from a where exists (select 1 from b where num=a.num)
9、索引并不是越多越好
索引固然可以提高相应的 SELECT 的效率,但同时也降低了 INSERT 及 UPDATE 的效。
因为 INSERT 或 UPDATE 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过 6 个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
10、尽量使用数字型字段
(1)因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
(2)而对于数字型而言只需要比较一次就够了;
(3)字符会降低查询和连接的性能,并会增加存储开销;
所以:尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
11、尽可能的使用 varchar, nvarchar 代替 char, nchar
(1)varchar 变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间;
(2)char 按声明大小存储,不足补空格;
(3)其次对于查询来说,在一个相对较小的字段内搜索,效率更高;
因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
14、查询 SQL 尽量不要使用 select *,而是具体字段
最好不要使用返回所有:select * from t ,用具体的字段列表代替 “*”,不要返回用不到的任何字段。
select * 的弊端:
(1)增加很多不必要的消耗,比如 CPU、IO、内存、网络带宽;
(2)增加了使用覆盖索引的可能性;
(3)增加了回表的可能性;
(4)当表结构发生变化时,前端也需要更改;
(5)查询效率低;
15、将需要查询的结果预先计算好
将需要查询的结果预先计算好放在表中,查询的时候再 Select,而不是查询的时候进行计算。
16、IN 后出现最频繁的值放在最前面
如果一定用 IN,那么:在 IN 后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数。
17、尽量使用 EXISTS 代替 select count (1) 来判断是否存在记录。
count 函数只有在统计表中所有行数时使用,而且 count (1) 比 count (*) 更有效率。
18、用批量插入或批量更新
当有一批处理的插入或更新时,用批量插入或批量更新,绝不会一条条记录的去更新。
(1)多条提交
INSERT INTO user (id,username) VALUES(1,'xx'); INSERT INTO user (id,username) VALUES(2,'yy');
(2)批量提交
INSERT INTO user (id,username) VALUES (1,'xx'),(2,'yy'); 默认新增 SQL 有事务控制,导致每条都需要事务开启和事务提交,而批量处理是一次事务开启和提交,效率提升明显,达到一定量级,效果显著,平时看不出来。
19、将不需要的记录在 GROUP BY 之前过滤掉
提高 GROUP BY 语句的效率,可以通过将不需要的记录在 GROUP BY 之前过滤掉。
下面两个查询返回相同结果,但第二个明显就快了许多。
低效:
SELECT JOB, AVG (SAL) FROM EMP GROUP BY JOB HAVING JOB='PRESIDENT' OR JOB='MANAGER' 高效:
SELECT JOB, AVG(SAL) FROM EMP WHERE JOB='PRESIDENT' OR JOB='MANAGER' GROUP BY JOB
20、避免死锁
在你的存储过程和触发器中访问同一个表时总是以相同的顺序;事务应经可能地缩短,在一个事务中应尽可能减少涉及到的数据量;永远不要在事务中等待用户输入。
21、索引创建规则:
表的主键、外键必须有索引;
数据量超过 300 的表应该有索引;
经常与其他表进行连接的表,在连接字段上应该建立索引;
经常出现在 WHERE 子句中的字段,特别是大表的字段,应该建立索引;
索引应该建在选择性高的字段上;
索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替;
正确选择复合索引中的主列字段,一般是选择性较好的字段;
复合索引的几个字段是否经常同时以 AND 方式出现在 WHERE 子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
如果复合索引中包含的字段经常单独出现在 WHERE 子句中,则分解为多个单字段索引;
如果复合索引所包含的字段超过 3 个,那么仔细考虑其必要性,考虑减少复合的字段;
如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
频繁进行数据操作的表,不要建立太多的索引; 删除无用的索引,避免对执行计划造成负面影响;
表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。
另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。 尽量不要对数据库中某个含有大量重复的值的字段建立索引。
22、在写 SQL 语句时,应尽量减少空格的使用
查询缓冲并不自动处理空格,因此,在写 SQL 语句时,应尽量减少空格的使用,尤其是在 SQL 首和尾的空格(因为查询缓冲并不自动截取首尾空格)。
23、每张表都设置一个 ID 做为其主键
我们应该为数据库里的每张表都设置一个 ID 做为其主键,而且最好的是一个 INT 型的(推荐使用 UNSIGNED),并设置上自动增加的 AUTO_INCREMENT 标志。
24、使用 explain 分析你 SQL 执行计划
(1)type
system:表仅有一行,基本用不到;
const:表最多一行数据配合,主键查询时触发较多;
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了 const 类型;
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
range:只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可以使用 range;
index:该联接类型与 ALL 相同,除了只有索引树被扫描。这通常比 ALL 快,因为索引文件通常比数据文件小;
all:全表扫描;
性能排名:system > const > eq_ref > ref > range > index > all。 实际 sql 优化中,最后达到 ref 或 range 级别。
(2)Extra 常用关键字
Using index:只从索引树中获取信息,而不需要回表查询;
Using where:WHERE 子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果 Extra 值不为 Using where 并且表联接类型为 ALL 或 index,查询可能会有一些错误。需要回表查询。
Using temporary:mysql 常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的 GROUP BY 和 ORDER BY 子句时;
25、当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去 fetch 游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。
这样一来,MySQL 数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
26、将大的 DELETE,UPDATE、INSERT 查询变成多个小查询
能写一个几十行、几百行的 SQL 语句是不是显得逼格很高?然而,为了达到更好的性能以及更好的数据控制,你可以将他们变成多个小查询。
27、合理分表 尽量控制单表数据量的大小,建议控制在 500 万以内
500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
作者:京东科技 梁发文
来源:京东云开发者社区 转载请注明来源
新闻资讯
-
2024-05-13 09:05:39
电竞圈“地震”前兆?贴吧100多人12377举报LGD宣传菠菜
-
2024-05-13 09:05:11
楼市迎巨变!国家部署二次房改,释放3大信号,消除买不起房顾虑
-
2024-05-13 09:04:36
游戏党狂喜,微软 Win11 将优化窗口模式和无边框模式下的游戏体验
-
2024-05-13 09:03:20
300个小众优雅的女生英文名
-
2024-05-13 09:03:09
欧洲留学哪个国家最好,欧洲留学最佳国家盘点
-
2024-05-13 09:01:59
事关免疫力,身体上的这种“肉”最好多一点!养护方法奉上~

 QQ客服
QQ客服 

